
高校数学で学ぶように,微分可能な1変数関数$f$に対しては,方程式$\displaystyle\od{f}{x}(x)=0$を解けば,$f$が極値をもつ$x$の候補が得られるのでした.
これは2変数関数になっても同様で,$f(x,y)=5x^2+5y^2+6xy-2$のような微分可能な2変数関数$f$に対しては,方程式

を解けば,$f$が極値をとる点$(x,y)$の候補が得られます.しかし,この問題が次のようになると,そう簡単ではなくなります.
制約条件$y=x-3$上で$f(x,y)=5x^2+5y^2+6xy-2$で定まる2変数関数$f$が極値をとる点$(x,y)$の候補を求めよ.
つまり,$x$と$y$に制約条件(この問題では$y=x-3$)がある場合には,単純に$f$の偏導関数から極値の候補を求めることができません.
この問題では制約条件$y=x-3$が簡単なので$y$を消去して1変数に帰着させても解けますが,もっと複雑な制約条件ならそうもいきませんね.
そこで,曲線や直線上といった制約条件下での関数の極値を求めるための方法として,ラグランジュ(Lagrange)の未定乗数法があります.
この記事では
- ラグランジュの未定乗数法の直感的な考え方
- ラグランジュの未定乗数法の具体例
を説明します.
ラグランジュの未定乗数法の直感的な理解
1変数関数の場合には,定義域があっても単純な微分で極値点を求めることができるので,ラグランジュの未定乗数法は必要ありません.
そのため,ラグランジュの未定乗数法が必要となるのは2変数以上の場合です.
偏導関数
関数$f$の$x$に関する偏導関数$\displaystyle\pd{f}{x}$によって,$y$を固定したときの$f$の$x$の増減を考えることができます.
つまり,$\displaystyle\od{f}{x}$によって,$x$軸に平行な向きの増減が分かります.

このように,偏導関数を考えることで軸に平行な方向の増減を考えることはできますが,軸に平行でない直線や曲線上での増減は単純に偏導関数を考えるだけでは分かりません.
これにより,制約条件のもとでは単に偏導関数を考えるだけでは都合が悪いわけですね.
極値をとる2つのパターン
具体的に,冒頭で書いた次の問題を考えましょう.
制約条件$y=x-3$上で$f(x,y)=5x^2+5y^2+6xy-2$で定まる2変数関数$f$が極値をとる点$(x,y)$の候補を求めよ.
$z=f(x,y)$とすると$x$と$y$を決めると$z$が決まり,この方程式のグラフは$xyz$空間上に描くことができます.
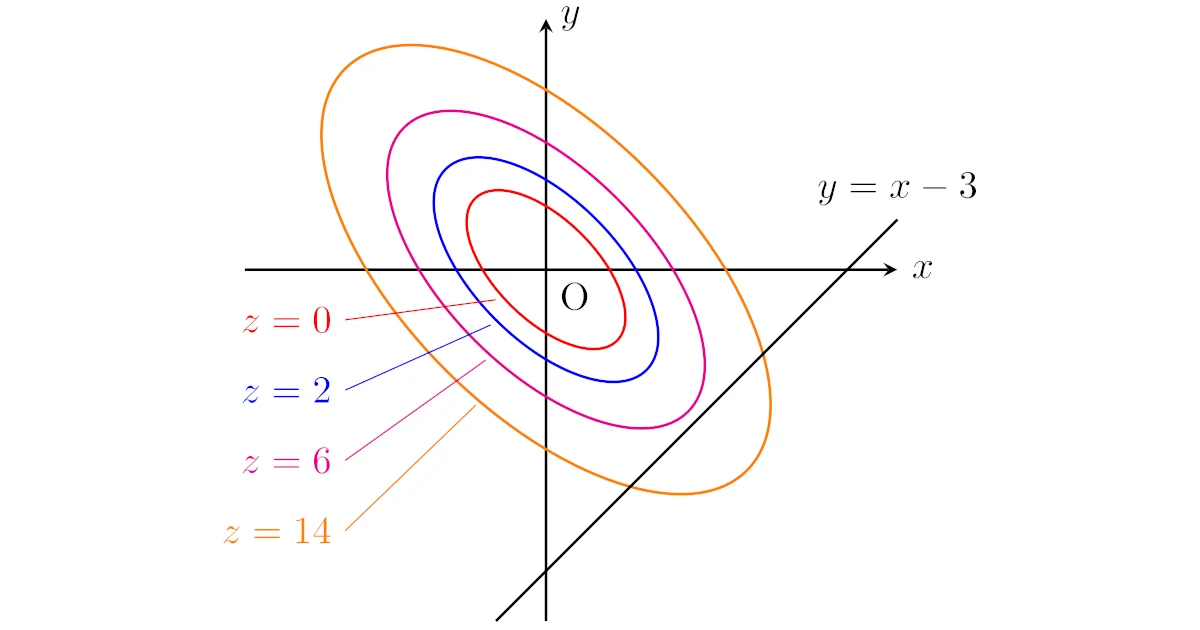
この問題では,$f(x,y)$は2次の係数が全て正の2次式なので,$z=f(x,y)$のグラフは下に凸な以下のような「お椀型」の曲面となりますね.
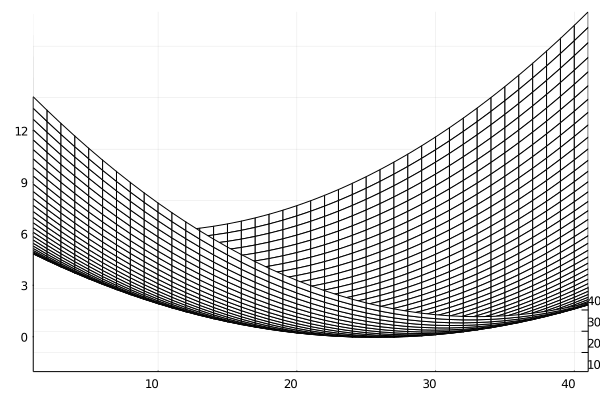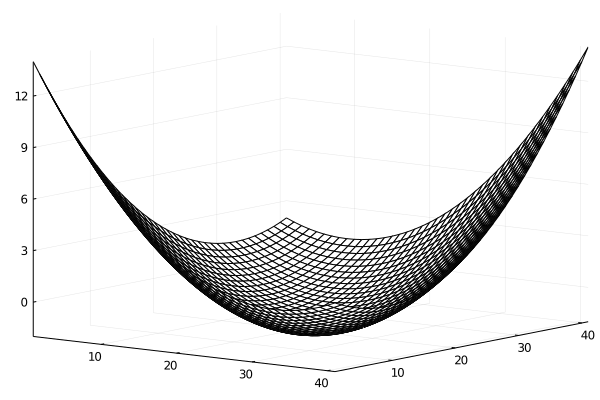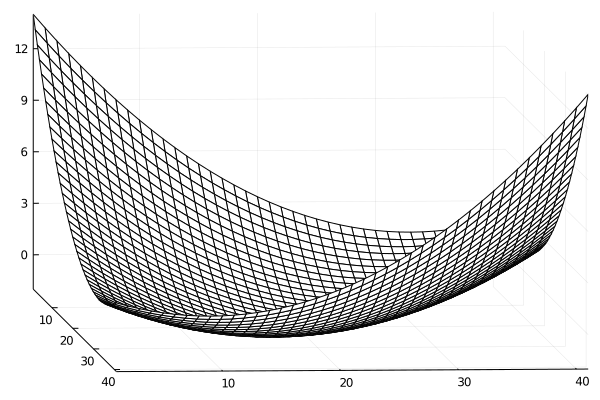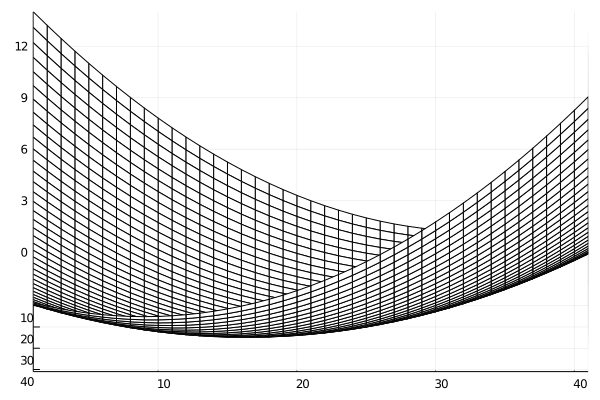
このグラフの「等高線」は以下のようになります.

$z=0,2,6,14$と$z$が大きくなるにつれて等高線が広がっているわけですね.
パターン1
こうみるとうまく$z=C$を取れば,等高線$f(x,y)=C$は制約条件$y=x-3$のグラフと接するようにできそうです.
もし等高線$f(x,y)=C$と$y=x-3$が点$(a,b)$で接するなら,下図のようになります.

さて,この等高線$f(x,y)=C$は$xy$平面を2つの領域に分割しており,
- 等高線$f(x,y)=C$の内部では$f(x,y)<C$
- 等高線$f(x,y)=C$の外部では$f(x,y)>C$
となっていますから,制約条件$y=x-3$上の点$(x,y)$は$f(x,y)\ge C$を満たし,$f(a,b)=C$だから,制約条件$y=x-3$のもとでの$f(x,y)$の最小値は$C$であることが分かりますね.
このように「制約条件$g(x,y)=0$のグラフ」と「$z=f(x,y)$の等高線」が接するような点$(a,b)$を見つけることができれば,この点$(a,b)$は極値となりえますね.
いま考えている問題では$g(x,y)=y-x+3$とすれば,制約条件は$g(x,y)=0$となりますね.
さて,制約条件$g(x)=0$のグラフと等高線$f(x,y)=C$が点$(a,b)$で接するなら
- $g(x,y)=0$上の点$(a,b)$での法線ベクトル$\nabla g(a,b)=\bmat{\pd{g}{x}(a,b)\\\pd{g}{y}(a,b)}$
- $f(x,y)=C$上の点$(a,b)$での法線ベクトル$\nabla f(a,b)=\bmat{\pd{f}{x}(a,b)\\\pd{f}{y}(a,b)}$
は平行となりますね.

このとき,($\nabla{g}\neq\m{0}$なら)ある$\mu\in\R$が存在して

が成り立ちます.よって,この等式が成り立つとき,点$(a,b)$は極値となり得ます.
パターン2
今考えていた制約条件$y=x-3$は滑らかな曲線でしたが,制約条件によってはグラフが「尖る」ことがあります.
このような尖った点では接ベクトルを考えることができませんが,もしこのグラフの尖った点が等高線$f(x,y)=C$にタッチしてすぐに引き返す状況になっていれば極値をとりうるわけです.
のちにラグランジュの未定条数法の具体例を考えますが,そこでの例2がこのパターン2に相当します.
$g$が微分可能であるとすれば,制約条件$g(x,y)=0$のグラフが尖る可能性があるのは$g$の速度が$0$になるような場合です.つまり,$g(x,y)=0$上の点$(a,b)$が

を満たしていれば,$g(x,y)=0$のグラフは点$(a,b)$で尖っている可能性がありますね.
つまり,このような$(a,b)$は極値の候補になるわけですね.
ラグランジュの未定乗数法
以上の考察をまとめた以下の定理がラグランジュの未定乗数法です.
[ラグランジュの未定乗数法(2変数の場合)] 関数$f,g:\R^2\to\R$は共に$C^1$級であるとし,束縛条件$g(x,y)=0$のグラフを$S$とする.
このとき,次の(1), (2)のいずれかを満たす点$(a,b)\in S$のみ$f$の$S$上の極値点となりうる.
- $\displaystyle\pd{g}{x}(a,b)=\displaystyle\pd{g}{y}(a,b)=0$
- $\bmat{\pd{f}{x}(a,b)\\\pd{f}{y}(a,b)}=\mu\bmat{\pd{g}{x}(a,b)\\\pd{g}{y}(a,b)}$かつ$g(a,b)=0$を満たす$\mu\in\R$が存在する.
ラグランジュの未定乗数法は$S$上の極値をもつための必要条件を述べているだけであり,(1)または(2)を満たしていても極値となるかどうかは分からないことに注意してください.
さて,このままでも何も間違いなはいのですが,このラグランジュの未定乗数法の(2)はラグランジュ関数と呼ばれる

を用いると,

となるので,(2)は次のようにすっきり書き換えることができますね.
[ラグランジュの未定乗数法(2変数の場合)] 関数$f,g:\R^2\to\R$は共に$C^1$級であるとし,束縛条件$g(x,y)=0$のグラフを$S$とする.
このとき,次の(1), (2)のいずれかを満たす点$(a,b)\in S$のみ$f$の$S$上の極値点となりうる.
- $\displaystyle\pd{g}{x}(a,b)=\displaystyle\pd{g}{y}(a,b)=0$
- $\Phi(x,y,\lambda)=f(x,y)-\lambda g(x,y)$に対して,$\nabla_{x,y,\lambda}\Phi(a,b,\mu)=\m{0}$を満たす$\mu\in\R$が存在する
のちに2変数とは限らない一般の場合の証明を与えますが,2変数の場合の場合の証明も与えておきましょう.
点$(a,b)$が$f$の$S$上の極値点であるとし,$\bmat{\pd{g}{x}(a,b)\\\pd{g}{y}(a,b)}\neq\bmat{0\\0}$であるとし,条件2が成り立つこと示せばよい.
$\bmat{\pd{g}{x}(a,b)\\\pd{g}{y}(a,b)}\neq\bmat{0\\0}$が成り立つとき
- $\pd{g}{x}(a,b)\neq0$の場合
- $\pd{g}{y}(a,b)\neq0$の場合
がありうるが,どちらでも証明は同様なので$\pd{g}{x}(a,b)\neq0$の場合を考えても一般性を失わない.
ここで,$\mu\in\R$を

で定めると
- $a,b\in S$より$g(a,b)=0$
- $\mu$の定義より$\pd{f}{x}(a,b)-\mu\pd{g}{x}(a,b)=0$
が成り立つから,あとは$\pd{f}{y}(a,b)=\pd{g}{y}(a,b)$を示せばよい.
$\pd{g}{x}(a,b)\neq0$より陰関数定理が適用できる.すなわち
- $(a,b)$の近傍$W\times V\subset \R^2$ $(W\subset\R,V\subset\R)$
- $C^1$級関数$h:V\to W$
が存在して
- $(x,y)\in W\times V$なら,$(x,y)\in S \iff x=h(y)$
- $\pd{h}{y}(b)=-\frac{\pd{g}{y}(a,b)}{\pd{g}{x}(a,b)}$
をみたす.また,$F:V\to \R$を$F(y):=f(h(y))$で定めると
- $(h(b),b)\in S$
- $f$が$S$上の点$(a,b)\in S$で極値をとる
より,$F$は$V$上の点$b$で極値をもつから$\pd{F}{y}(b)=0$を満たす.よって,$\mu$の定義と併せると

だから$\pd{f}{y}(a,b)=\mu\pd{g}{y}(a,b)$が従う.
ラグランジュの未定乗数法の具体例
それでは,ラグランジュの未定乗数法の具体例な使い方をみましょう.
具体例1
関数$f$, $g$を
- $f(x,y)=(x-1)^2+(y-1)^2$
- $g(x,y)=x^2+y^2-4$
で定める.束縛条件$g(x,y)=0$のもとでの$f$の極値点の候補をラグランジュの未定乗数法により求めよ.
束縛条件$g(x,y)=0$のグラフ$S$は原点中心,半径$2$の円で,このグラフ$S$上の極値点$(a,b)$を求める.

(1) $\displaystyle\pd{g}{x}(x,y)=2x$, $\displaystyle\pd{g}{y}(x,y)=2y$なので

であるが,$(0,0)\notin S$なので$\pd{g}{x}(a,b)=\pd{g}{y}(a,b)=0$となる$(a,b)\in S$は存在しない.
(2) $\Phi(x,y,\lambda)=f(x,y)-\lambda g(x,y)$とおくと

であり,この連立方程式の解$(x,y,\lambda)=(a,b,\mu)$が存在すれば点$(a,b)$が極値点の候補となる.
第$3$成分の両辺を$(1-\lambda)^2$倍して,$(1-\lambda)x=1$と$(1-\lambda)y=1$を代入することにより

であり,それぞれの$\lambda$を$(1-\lambda)x=1$と$(1-\lambda)y=1$に代入して,複号同順で

となって,$\nabla_{x,y,\lambda}\Phi(x,y,\lambda)=\m{0}$の解が求まった(よって,存在した).
(1), (2)より,極値点の候補$\bra{\pm\sqrt{2},\pm\sqrt{2}}$が得られた.
具体例2
関数$f$, $g$を
- $f(x,y)=(x-1)^2+y^3$
- $g(x,y)=x^2-y^3$
で定める.束縛条件$g(x,y)=0$のもとでの$f$の極値点の候補をラグランジュの未定乗数法により求めよ.
束縛条件$g(x,y)=0$のグラフ$S$は下図のようになっており,$S$上の極値点$(a,b)$を求めましょう.

(1) $\pd{g}{x}(x,y)=2x$, $\pd{g}{y}(x,y)=-3y$なので
であり,$(0,0)\in S$なので$(0,0)$は極値点の候補である.
(2) $\Phi(x,y,\lambda)=f(x,y)-\lambda g(x,y)$とおくと

であり,この連立方程式の解$(x,y,\lambda)=(a,b,\mu)$が存在すれば点$(a,b)$が極値点の候補となる.
第2成分より$\lambda=-1$または$y=0$が成り立つ.
もし$y=0$なら,第3成分から$x=0$となるが,これは第1成分に矛盾するから$y\neq0$である.
また,$\lambda=-1$なら,第1成分から$x=\frac{1}{2}$,さらに第3成分から$y=\frac{1}{\sqrt[3]{4}}$となって,$\nabla_{x,y,\lambda}\Phi(x,y,\lambda)=\m{0}$の解が求まった(よって,存在した).
(1), (2)より,極値点の候補$(0,0)$, $\bra{\dfrac{1}{2},\dfrac{1}{\sqrt[3]{4}}}$が得られた.
3変数以上の場合のラグランジュの未定乗数法
2変数の場合のラグランジュの未定乗数法を理解できていれば,以下の一般の$N$変数の場合も同様に理解できます.
[ラグランジュの未定乗数法] 関数$f,g_1,\dots,g_k:\R^N\to\R$は全て$C^1$級であるとし,束縛条件$g_1(\m{x})=\dots=g_k(\m{x})=0$のグラフを$S$とする.
このとき,次の(1), (2)のいずれかを満たす点$\m{a}\in S$のみ$f$の$S$上の極値点となりうる.
- $\rank{\bmat{\pd{g_1}{x_1}(\m{a})&\dots&\pd{g_1}{x_N}(\m{a})\\\vdots&\ddots&\vdots\\\pd{g_k}{x_1}(\m{a})&\dots&\pd{g_k}{x_N}(\m{a})}}<k$
- $\Phi(\m{x},\m{\lambda})=f(\m{x})-\m{\lambda}\cdot\m{g}(\m{x})$で定まる$\Phi:\R^N\times\R^k\to\R$に対して,$\nabla_{\m{x},\m{\lambda}}{\Phi}(\m{a},\m{\mu})=\m{0}$となる$\m{\mu}\in\R^k$が存在する.
ただし,$\m{\lambda}=\bmat{\lambda_1\\\vdots\\\lambda_k}$, $\m{g}=\bmat{g_1\\\vdots\\g_k}$であり,$\m{\lambda}\cdot\m{g}(\m{x})$は$\m{\lambda}$と$\m{g}(\m{x})$の通常の内積である.
具体例
$\m{x}=\bmat{x_1\\x_2\\x_3}$とし,関数$g_1,g_2:\R^3\to\R$を

で定め,束縛条件$g_1(\m{x})=g_2(\m{x})=0$の場合を考えます($N=3$, $k=2$の場合).
(1)

だから,$p\in\R$が存在して$\bmat{p\\p\\0}\in S$となれば,ラグランジュの未定乗数法の(1)が成り立ちます.
実際,$g_1(p,p,0)=2p$, $g_2(p,p,0)=2p^2$より$p=0$で$\bmat{p\\p\\0}\in S$となるので,点$\bmat{p\\p\\0}$でラグランジュの未定乗数法の(1)をみたし,極値点の候補となります.
(2) 関数$\Phi:\R^3\times\R^2\to\R$を

で定めます.このとき,

の解$(\m{x},\m{\lambda})$が極値点の候補となります(いまは$f$を与えていないのでここまで).
ラグランジュの未定乗数法の証明
それではラグランジュの未定乗数法を証明します.
[ラグランジュの未定乗数法(再掲)] 関数$f,g_1,\dots,g_k:\R^N\to\R$は全て$C^1$級であるとし,束縛条件$g_1(\m{x})=\dots=g_k(\m{x})=0$のグラフを$S$とする.
このとき,次の(1), (2)のいずれかを満たす点$\m{a}\in S$のみ$f$の$S$上の極値点となりうる.
- $\rank\brc{\displaystyle\pd{\m{g}}{x_1}(\m{a}),\dots,\pd{\m{g}}{x_N}(\m{a})}<k$
- $\Phi(\m{x},\m{\lambda})=f(\m{x})-\m{\lambda}\cdot\m{g}(\m{x})$で定まる$\Phi:\R^N\times\R^k\to\R$に対して,$\nabla_{\m{x},\m{\lambda}}{\Phi}(\m{a},\m{\mu})=\m{0}$となる$\m{\mu}\in\R^k$が存在する.
ただし,$\m{\lambda}=\bmat{\lambda_1\\\vdots\\\lambda_k}$, $\m{g}=\bmat{g_1\\\vdots\\g_k}$であり,$\cdot$は標準内積を表す.
条件(1)の行列は先ほどと少し違うように見えるかも知れませんが,任意の$i=1,\dots,N$に対して

なので,さっきと同じ行列であることが分かりますね.
点$\m{a}$が$f$の$S$上の極値点であるとし,$\rank{\brc{\displaystyle\pd{\m{g}}{x_1}(\m{a}),\dots,\pd{\m{g}}{x_N}(\m{a})}}=k$であるとする.
このとき$k\le N$であり,また$\rank{\displaystyle\brc{\pd{\m{g}}{x_1}(\m{a}),\dots,\pd{\m{g}}{x_k}(\m{a})}}=k$としても一般性を失わない.
ここで,$\m{\mu}\in\R^k$と$\Phi:\R^N\times\R^k\to\R$を

で定めると,$\nabla_{\m{x},\m{\lambda}}{\Phi}(\m{a},\m{\mu})=\m{0}$が成り立つことを示せば良い.これを以下3ステップに分けて示す.
[ステップ1] $\displaystyle\pd{\Phi}{\lambda_i}(\m{a},\m{\mu})=0$ ($i=1,\dots,k$)を満たすことを示す.
$\m{a}\in S$より$g_i(\m{a})=0$ ($i=1,\dots,k$)なので

が従う.
[ステップ2] $\displaystyle\pd{\Phi}{x_i}(\m{a},\m{\mu})=0$ ($i=1,\dots,k$)を満たすことを示す.
$\Phi$と$\m{\mu}$の定義から,任意の$i=1,\dots,k$に対して

が従う.
[ステップ3] $\displaystyle\pd{\Phi}{x_i}(\m{a},\m{\mu})=0$ ($i=k+1,\dots,N$)を満たすことを示す.
$\m{a}=(\m{a}_1,\m{a}_2)\in\R^k\times\R^{N-k}$とする.$\rank{\brc{\displaystyle\pd{\m{g}}{x_1}(\m{a}),\dots,\pd{\m{g}}{x_k}(\m{a})}}=k$より$\m{a}$の近傍で陰関数定理が適用できる.すなわち,
- $\m{a}$の近傍$W\times V\subset \R^N$ $(W\subset\R^k,V\subset\R^{N-k})$
- $C^1$級関数$\m{h}=\bmat{h_1\\\vdots\\h_k}:V\to W$
が存在して,任意の$\m{x}=(\m{x}_1,\m{x}_2)\in W\times V$は

かつ

をみたす.$\m{\mu}$の定義と併せると

だから,任意の$i=k+1,\dots,N$に対して,

となる.
また,$F:V\to \R$を

で定める.このとき,$(h_1(\m{x}_2),\dots,h_k(\m{x}_2),\m{x}_2) \in S$であり,$f$が$S$上の点$\m{a}$で極値をとるという仮定より,$F$は$V$上の点$\m{a}_2$で極値をもつから,$\displaystyle\pd{F}{x_{k+1}}(\m{a}_2)=\dots=\pd{F}{x_N}(\m{a}_2)=0$を満たす.
よって,任意の$i=k+1,\dots,N$に対して,

が従う.
参考文献
以下は参考文献です.
解析入門
[杉浦光男 著/東京大学出版会]

解析学の教科書としては非常に有名で,理論系で解析がしっかり必要となる人は持っておいてよいテキストです.
- 第1巻で1変数の微分積分学
- 第2巻で多変数の微分積分学
を扱っています.本書に対応した演習書「解析演習」も出版されています.
本書の特徴としては
- 数学的に厳密に書かれている
- 基本的な微分積分学の知識体系は網羅されている
の2点が挙げられます.
このため,辞書的に使う教科書という位置付けて持っている人も多いようです.
なお,この記事の内容は第1巻に載っています.
微分積分学
[笠原晧司 著/サイエンス社]

微分積分学の教科書として有名な名著です.
具体例を多く扱いイメージを掴むことに重点を置きつつ,議論もきっちりしているため,大学1年生の微分積分学をしっかり学びたい人には心強い味方になると思います.
具体例のレベルは基本的なものに加えて少々難しいものも含まれているので,いろいろな具体例に触れたい人は持っておいてもよいでしょう.
このため,しっかり数学をやりたい人の微分積分学の導入としてオススメできる一冊です.
コメント
とても明快なご説明ありがとうございました。イメージがつかめず困っていたため、大変助かりました。
コメントをありがとうございます!
公式を見ても,なかなかイメージか掴みづらいものもありますよね.
お役に立てたようで良かったです!