
あるテストを受けた生徒たちについて
- 勉強時間$x$
- テストの成績$y$
のデータをとったとき,「勉強時間」が長いほど「テストの成績」は高いことは予想できますが,このことをデータからきちんと立証するにはどのように考えればよいでしょうか?
2種類の対応するデータについて
- 一方が大きいとき,他方も大きいことを正の相関
- 一方が大きいとき,他方は小さいことを負の相関
と言い,相関の正負は共分散を求めることで分かります.
共分散の値を調整してできる相関係数を調べると相関の正負に加えて,相関の強さまで分かります.相関係数は共分散を学んだ後に学びます.
この記事では
- 散布図と相関
- 共分散とは何か?
を説明します.
「統計データの記述」の一連の記事
散布図と相関
あるテストを受けた8人の生徒について
- 勉強時間$x$
- テストの点数$y$
が以下の表のようになったとしましょう.
| 人 | A | B | C | D | E | F | G | H |
|---|---|---|---|---|---|---|---|---|
| 勉強時間$x$ | 2 | 6 | 8 | 3 | 13 | 10 | 5 | 9 |
| テストの点数$y$ | 24 | 60 | 63 | 40 | 92 | 85 | 43 | 49 |
散布図
この勉強時間$x$とテストの点数$y$のデータは
- 横軸を勉強時間$x$
- 縦軸をテストの点数$y$
として,下図のように$xy$平面上に図示することができます.

このように,2つのデータの組$(x,y)$を$xy$平面上にプロットした図を散布図といい,原因となる$x$を説明変数,その結果となる$y$を目的変数などといいます.
正の相関と負の相関
上の散布図を見たとき,点の集まりは右上がりの傾向があるように見えます.つまり,「勉強時間が長いほど,テストの点数が高い傾向がある」ということが見てとれます.
このように,2種類のデータ$x$, $y$があったとき,
- 一方のデータが大きいときに他方のデータも大きい傾向があることを正の相関がある
- 一方のデータが大きいときに他方のデータが小さい傾向があることを負の相関がある
といいます.これら正の相関と負の相関を併せて相関(または相関関係)といいます.
[正の相関]

[負の相関]

他にも,例えば
- 「プールの利用者数」と「アイスの売り上げ」は正の相関
- 「気温」と「インフルエンザの患者数」は負の相関
があることが予想できますね.
相関関係と因果関係
相関関係と因果関係はしっかり区別しておくことが大切です.
例えば,1日の「プールの利用者数」と「アイスの売り上げ」のデータをとったとき,「プールの利用者数」と「アイスの売り上げ」には正の相関があることでしょう.
しかし,「プールの利用者数が多くなるからアイスの売り上げが上がる」わけではないし,「アイスの売り上げが上がるからプールの利用者数が多くなる」わけでもありません.
つまり,「プールの利用者数」と「アイスの売り上げ」の間に相関関係はあっても,因果関係はなさそうです.
このように,相関関係があっても因果関係がないような相関を擬似相関などといいます.
共分散
それでは,2つの関係するデータの相関の正負を表す共分散の説明に移ります.
先ほどの勉強時間$x$とテストの点数$y$のデータをもとに,2ステップで共分散の考え方を説明します.
| 人 | A | B | C | D | E | F | G | H |
|---|---|---|---|---|---|---|---|---|
| 勉強時間$x$ | 2 | 6 | 8 | 3 | 13 | 10 | 5 | 9 |
| テストの点数$y$ | 24 | 60 | 63 | 40 | 92 | 85 | 43 | 49 |
ステップ1($x$, $y$の平均値で散布図を分割する)
共分散を求めるためには,まず$x$の平均値$\overline{x}$と$y$の平均値$\overline{y}$を求めます:
\begin{align*}&\overline{x}=\frac{2+6+8+3+13+10+5+9}{8}=7,
\\&\overline{y}=\frac{24+60+63+40+92+85+43+49}{8}=57.\end{align*}
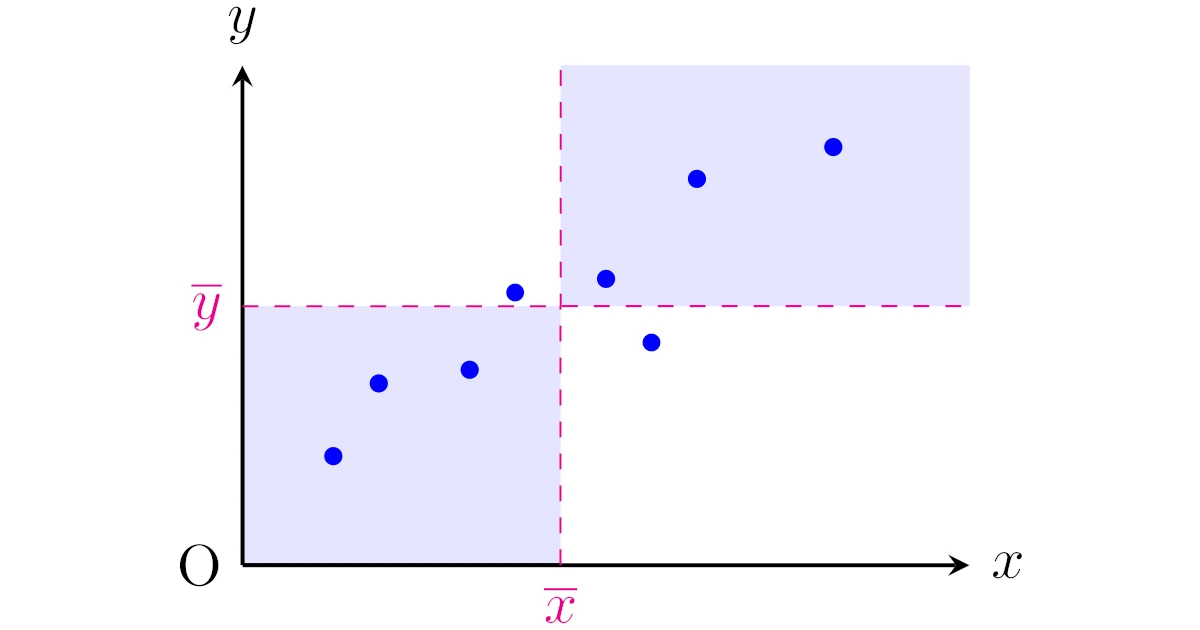
これらの平均値をもとに,下図のように散布図を4つの領域に分けます.

この4つの領域のうち
- 右上と左下の領域には点が多く
- 左上と右下の領域には点が少ない
ことが見て取れますが,一般に$x$と$y$に正の相関があるなら右上と左下に点が集まりそうです.
一方で,$x$と$y$に負の相関があるなら右下と左上に点が集まりそうですね.
[正の相関の場合]

[負の相関の場合]

ステップ2($(x_i-\overline{x})(y_i-\overline{y})$の正負で領域を判断する)
散布図の点$(x_i,y_i)$に対して$(x_i-\overline{x})(y_i-\overline{y})$は$(x_i,y_i)$が4つの領域のどこに入っているかで下図のように変わります.

よって
- $(x_i-\overline{x})(y_i-\overline{y})>0$となる点$(x_i,y_i)$が多いほど,右上と左下にデータが多いので正の相関
- $(x_i-\overline{x})(y_i-\overline{y})<0$となる点$(x_i,y_i)$が多いほど,左上と右下にデータが多いので負の相関
と言えそうですね.
共分散の定義
以上の2ステップから共分散を次のように定義します.
[共分散]2種類のデータ$x_1,x_2,\dots,x_n$と$,y_1,y_2,\dots,y_n$に対して,それぞれの平均を$\overline{x}$, $\overline{y}$とするとき
\begin{align*}C_{xy}&=\frac{(x_1-\overline{x})(y_1-\overline{y})+(x_2-\overline{x})(y_2-\overline{y})+\dots+(x_n-\overline{x})(y_n-\overline{y})}{n}\end{align*}
をこのデータの組$(x,y)$の共分散(covariance)という.
和の記号$\sum$を用いると$C_{xy}=\frac{1}{n}\sum\limits_{k=1}^{n}(x_i-\overline{x})(y_i-\overline{y})$とも表せますね.
共分散$C_{xy}$の定義から
- 共分散$C_{xy}>0$が正なら$(x_i-\overline{x})(y_i-\overline{y})>0$となるデータの組$(x_i,y_i)$が多い
- 共分散$C_{xy}<0$が負なら$(x_i-\overline{x})(y_i-\overline{y})>0$となるデータの組$(x_i,y_i)$が多い
ということになるので
- $C_{xy}>0$であれば2種類のデータは正の相関がある
- $C_{xy}<0$であれば2種類のデータは負の相関がある
と解釈できますね.
共分散の具体例
具体的に上の勉強時間$x$とテストの点数$y$の共分散を求めましょう.
| 人 | A | B | C | D | E | F | G | H |
|---|---|---|---|---|---|---|---|---|
| 勉強時間$x$ | 2 | 6 | 8 | 3 | 13 | 10 | 5 | 9 |
| テストの点数$y$ | 24 | 60 | 63 | 40 | 92 | 85 | 43 | 49 |
$\overline{x}=7$, $\overline{y}=57$であることから
\begin{align*}C_{xy}&=\frac{1}{8}\{(2-7)(24-57)+(6-7)(60-57)
\\&\quad+(8-7)(63-57)+(3-7)(40-57)+(13-7)(92-57)
\\&\quad+(10-7)(85-57)+(5-7)(43-57)+(9-7)(49-57)\}
\\&=\frac{165-3+6+68+210+84+28-16}{8}
\\&=\frac{271}{4}=67.75\end{align*}
となります.
$C_{xy}>0$なので,散布図の見た目通り正の相関になっていることが共分散からも分かりました.
参考文献
以下は参考文献です.
改訂版 統計検定2級対応 統計学基礎
[日本統計学会 編/東京図書]

統計検定2級は「大学基礎科目(学部1,2年程度)としての統計学の知識と問題解決能力」という位置付けであり,ある程度の数学的な処理能力が求められます.
そのため,統計検定2級を取得していると,一定以上の統計的なデータの扱い方を身に付けているという指標になります.
日本統計学会が実施する「統計検定」の2級の範囲に対応する教科書なので,「2級の試験範囲を確認する」くらいのつもりで持っておくのが良いかもしれません.
しかし,このテキストは表面的な説明に留まっているなど読みづらい部分も多いので,本書だけで2級の対策をするのは少し難しいと思います.
大学1年の微分積分学の知識は必要なので,もし自信がなければ統計検定3級からの挑戦を検討しても良いでしょう.
なお,本書については,以下の記事で書評としてまとめています.
【教科書紹介|統計検定2級対応 統計学基礎(日本統計学会編)】
本書の目次・必要な知識・良い点と気になる点・オススメの使い方などをレビューしています.
コメント