
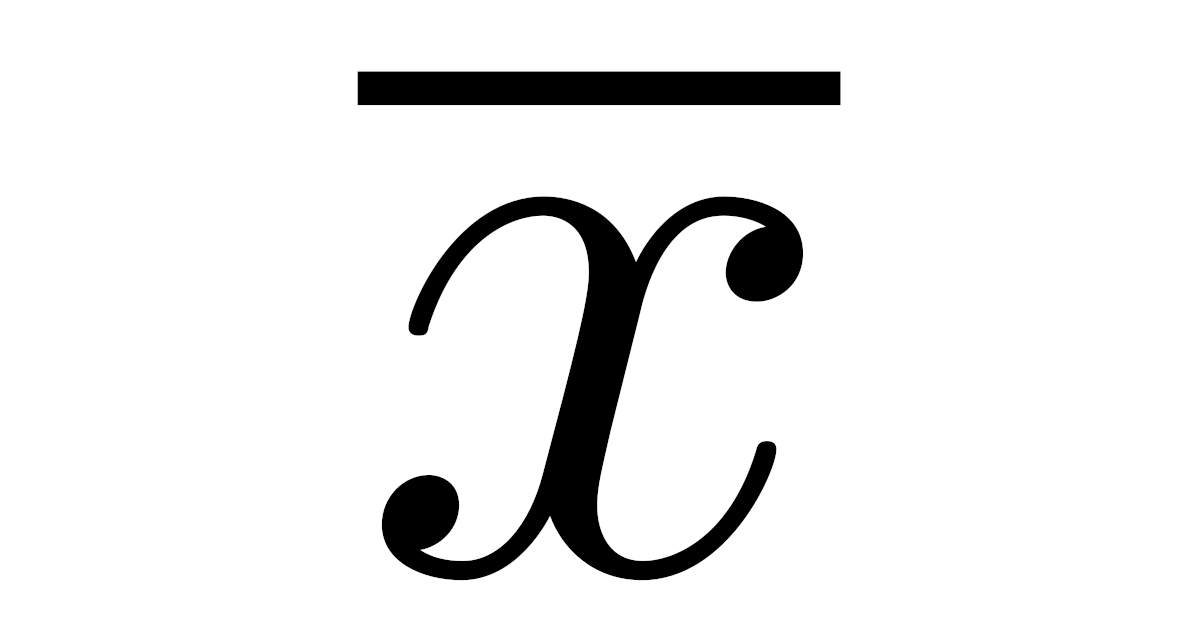
統計学(statistics)は実用的な数学の分野として,社会で広く応用されています.
ニュースで流れる選挙速報でそれほど開票されていないにもかかわらず「当選確実」と断言してしまえるのは統計学があってのものです.
他の例では「治療で用いられる薬が本当に効果があるのかどうか」というのも,統計学を用いて「効く」という根拠が示されて初めて使える薬として認められます.
さて,統計学はテストの成績,アンケート結果,薬の効果などの「データの集まりを処理するための数学」です.
データの集まりを大雑把に見るときには,データの平均値を考えることがよくありますが,実は平均値がデータを適切に表さないことがあります.
そのような場合にはデータの中央値を考えることが効果的であることもよくあります.
この記事では
- データの平均値
- データの中央値
- 平均値と中央値の違い(外れ値の影響)
について説明します.
「統計データの記述」の一連の記事
データの要約
以下のような7人のテストの成績を考えます.
| 人 | A | B | C | D | E | F | G |
|---|---|---|---|---|---|---|---|
| 点数 | 80 | 72 | 83 | 92 | 67 | 77 | 75 |
データの平均値
このとき「このデータは『どれくらい値』に集まっているか?」と問われたとき,多くの人は平均値を答えるのではないでしょうか?
データが$n$個あるときの平均値は以下のように定義されていますね.
データ$x_1,\dots,x_n$の平均値(mean)$\overline{x}$を
\begin{align*}\overline{x}=\frac{x_1+x_2+\dots+x_n}{n}\end{align*}
で定義する.
和の記号$\sum$を用いると$\overline{x}=\frac{1}{n}\sum\limits_{k=1}^{n}x_k$とも表せますね.
よって,上のデータでは平均値は点数の合計を人数で割った
\begin{align*}\frac{80+72+83+92+67+77+75}{7}=78\end{align*}
となりますね.
平均値はその名の通りデータを「平らに均した値」ということができ,例えば以下のように等しく7つに仕切られた水槽に深さが
\begin{align*}80\mrm{mm},\ 72\mrm{mm},\ 83\mrm{mm},\ 92\mrm{mm},\ 67\mrm{mm},\ 77\mrm{mm},\ 75\mrm{mm}\end{align*}
になるように水を入れます.

このとき,仕切りをすべて取り去ったときの水の高さが平均値の78mmですね.

実際,水の量は仕切りを取る前と取った後で変わらないことから青い部分の面積は等しいので,データが$n$個の場合には均した値$\overline{x}$は
\begin{align*}x_1+x_2+\dots+x_n=n\overline{x}\end{align*}
を満たすので,両辺を$n$で割って確かに先ほど定義した平均値に等しいことが分かりますね:
\begin{align*}\overline{x}=\frac{x_1+x_2+\dots+x_n}{n}\end{align*}
データの中央値
平均値と並んで大切なデータを要約する値として大切なものに中央値があり,中央値はその名の通り中央の値を指します.
例えば,先ほどのテストの点数を低い方から順に並べると
67点,72点,75点,77点,80点,83点,92点
となり,この中央の値は77点ですからテスト結果の中央値は77点となります.
いま具体的に考えた7人のテスト結果の場合には7は奇数なので「中央の値」が1つ決まりますが,データの数が偶数のときは「中央の2つの値の平均」を中央値とします.
たとえば,もう1人新たにテストを受けて85点だった場合,テスト結果は
67点,72点,75点,77点,80点,83点,85点,92点
となり,中央値は77点と80点の平均の78.5点となります.
データ$x_1,\dots,x_n$を小さい方から並べ直して$y_1,\dots,y_n$となったとする.このとき,$x_1,\dots,x_n$の中央値(median)を
- $n$が奇数のときは$y_{\frac{n+1}{2}}$
- $n$が偶数のときは$\dfrac{1}{2}(y_{\frac{n}{2}}+y_{\frac{n}{2}+1})$
で定義する.
平均値・中央値の外れ値の影響
上で説明した平均値・中央値の性質の大きな違いとして「外れ値の影響が出るかどうか」があります.
平均値の外れ値の影響
外れ値とは他のデータから大きく離れた値のことを言い,たとえばテスト結果が
22点,6点,11点,20点,15点,7点,3点,100点
となっていれば,100点は他のデータから大きく離れているので外れ値ということができます.このとき,平均値は
\begin{align*}\frac{22+6+11+20+15+7+3+100}{8}=\frac{184}{8}=23\end{align*}
なので,100点以外は全て平均値未満ということになります.このように,平均値は外れ値ひとつで大きく変化することがあります.
中央値の外れ値の影響
一方,中央値は
22点,6点,11点,20点,15点,7点,3点,100点
の場合でも
22点,6点,11点,20点,15点,7点,3点,30点
の場合でも変わりません.つまり,平均値とは違って中央値は外れ値の影響を受けないという特徴がありますね.
参考文献
改訂版 統計検定2級対応 統計学基礎
[日本統計学会 編/東京図書]

統計検定2級は「大学基礎科目(学部1,2年程度)としての統計学の知識と問題解決能力」という位置付けであり,ある程度の数学的な処理能力が求められます.
そのため,統計検定2級を取得していると,一定以上の統計的なデータの扱い方を身に付けているという指標になります.
日本統計学会が実施する「統計検定」の2級の範囲に対応する教科書なので,「2級の試験範囲を確認する」くらいのつもりで持っておくのが良いかもしれません.
しかし,このテキストは表面的な説明に留まっているなど読みづらい部分も多いので,本書だけで2級の対策をするのは少し難しいと思います.
大学1年の微分積分学の知識は必要なので,もし自信がなければ統計検定3級からの挑戦を検討しても良いでしょう.
なお,本書については,以下の記事で書評としてまとめています.
【教科書紹介|統計検定2級対応 統計学基礎(日本統計学会編)】
本書の目次・必要な知識・良い点と気になる点・オススメの使い方などをレビューしています.
コメント